Gemini 3 novità: vediamolo in azione

Dopo un periodo in cui sembrava che tutti i modelli di IA stessero più o meno navigando sulle stesse acque, Google ha fatto un salto clamoroso. Parliamo di Gemini 3, e fidati, non è il solito piccolo aggiornamento incrementale. È un cambio di categoria. Questo articolo è una prima riflessione a caldo, basata sui primi dati e sulle impressioni che stanno circolando, per capire cosa sta succedendo e perché questo modello sta lasciando tutti a bocca aperta.
1. Un salto quantico nei benchmark
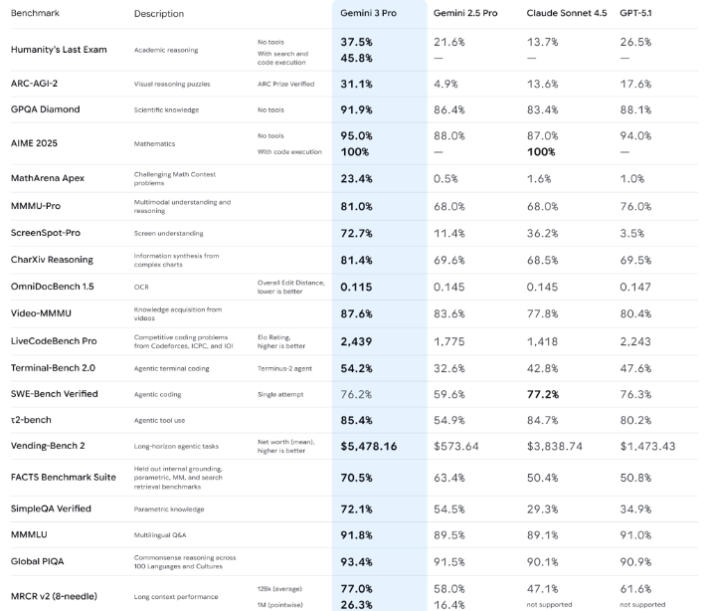
La dimostrazione di una nuova categoria
Per molto tempo, seguire i numeri dei benchmark di intelligenza artificiale era diventato quasi noioso. Vedevamo miglioramenti minimi, magari un passaggio dal 98% al 98.3%. In pratica, si era raggiunta una sorta di saturazione, un “plateau” dove i modelli come Cloud o GPT sembravano tutti allo stesso livello. Con Gemini 3, però, è iniziato qualcosa di completamente diverso. Non parliamo di piccoli passi avanti, ma di una vera e propria rivoluzione che lo pone in una categoria a parte.
Humanity last exam e arc-gi: l’asticella si alza
Quando si valuta un modello di IA, alcuni test sono considerati i più difficili perché richiedono capacità simili a quelle umane, come il ragionamento complesso e la comprensione del contesto. Due di questi benchmark sono fondamentali: Humanity Last Exam e ARC-AGI.
- Humanity Last Exam: Questo test misura la capacità del modello di risolvere attività che richiedono un certo tipo di ragionamento e comprensione del contesto, difficoltà che si pensava fossero imbattibili.
- Esempio 2025: Se prima la versione precedente di Gemini (la 2.5) si attestava intorno a un 26% di successo, e la concorrenza (come l’ultima versione di CGPT o Cloud) era ferma su quel livello, Gemini 3 arriva a un sorprendente 45,8%. Si parla del doppio rispetto alla versione precedente e di un distacco notevole dalla concorrenza.
- ARC-AGI (Abstraction and Reasoning Corpus): È un test che misura la comprensione di pattern e l’intelligenza spaziale. È un tipo di problema che un essere umano minimamente “skillato” risolve facilmente, ma dove i modelli di IA precedenti si incartavano, ottenendo risultati bassissimi (come 1-3%).
- Esempio 2025: Gemini 2.5 in questo test faceva un misero 4,9%. Gemini 3 schizza a 31,1%. Anche in questo caso, è più del doppio rispetto ai risultati ottenuti da Cloud e GPT, un risultato definito “fuori testa” dagli esperti.
Comprensione visuale e matematica
I miglioramenti non si fermano al ragionamento astratto, ma toccano anche ambiti molto pratici:
- ScreenSpot (Comprensione degli screenshot): Misura la capacità di un modello di riconoscere e comprendere ciò che è visualizzato su uno schermo. La versione precedente di Gemini faceva l’11%, GPT si fermava al 3,5%. Gemini 3 raggiunge il 72%. È un modello che sta praticamente “maxando” (portando al massimo) benchmark che sembravano intoccabili.
- Math Arena: In questo benchmark matematico, la media del mercato si aggirava sullo 0,05% – 1%. Gemini 3 raggiunge un incredibile 23%, distaccando tutti gli altri.
In sintesi, i numeri di Gemini 3 sono così sbalorditivi da far dire che i rilasci della concorrenza sembrano ormai “incrementali” e “indifferenti”, mentre questo è un evento di portata “clamorosa”.
2. Il segreto del successo: pretraining, post training e hardware
Cosa c’è dietro un salto di performance così grande?
Quando un modello di IA mostra un balzo in avanti così impressionante, la domanda è d’obbligo: come è stato fatto? Il co-leader di Google DeepMind ha svelato che il segreto di Gemini 3 risiede in due aree di lavoro massive: il pretraining e il post training, insieme a un aspetto hardware cruciale.
Lavorare sui dati: pretraining massiccio
Il pretraining è la fase in cui il modello viene “nutrito” con una quantità enorme di dati per imparare il linguaggio, la logica e le relazioni. Per Gemini 3, Google ha utilizzato una mole di dati e parametri così folle che, come si dice, non si saprebbe quanti zeri mettere sulla carta per scriverla.
- Esempio: Immagina di voler imparare tutto sullo sport. Il vecchio modello (Gemini 2.5) leggeva una biblioteca di 1.000 libri. Gemini 3, invece, ne ha letti 100.000, e questo non include solo i libri, ma anche video, articoli e conversazioni in tempo reale. Più dati di alta qualità il modello usa in questa fase iniziale, più profonda e versatile sarà la sua comprensione del mondo.
Lavorare sulla messa a punto: il post training
Il post training è il lavoro di affinamento che viene fatto dopo che il modello ha assorbito tutti i dati iniziali. È il momento in cui viene reso più sicuro, più utile e migliore nel seguire le istruzioni umane. Anche qui, c’è stato un investimento di lavoro enorme, che ha contribuito in modo significativo alle performance finali.
- Esempio: Tornando all’atleta, dopo aver letto tutti quei libri (pretraining), l’atleta deve allenarsi sul campo, correggendo la postura, perfezionando la tecnica e imparando a reagire in situazioni inaspettate. Questo è il post training: affinare le sue abilità per renderlo un campione non solo teorico, ma pratico.
L’indipendenza tecnologica: addio a nvidia?
Uno degli aspetti più interessanti, e una vera “brutta notizia” per i giganti dell’hardware, è che Google non ha utilizzato le GPU (Graphics Processing Unit) di Nvidia, l’hardware standard usato da quasi tutti gli altri modelli (come Open AI).
Invece, Gemini 3 è stato addestrato interamente con le TPU (Tensor Processing Unit), che sono l’hardware proprietario di Google.
- Esempio: Finora, Nvidia era il fornitore unico e insostituibile dei motori per tutte le auto da corsa. Google, dimostrando che le sue TPU possono ottenere risultati uguali o superiori a quelli di Nvidia, ha creato un precedente clamoroso.
Questo fatto pone una grande domanda: Google renderà le sue TPU disponibili ad altri, o diventerà un enorme vantaggio competitivo riservato solo a loro? In entrambi i casi, è un annuncio “clamoroso” che mette in discussione l’attuale leadership tecnologica nell’hardware per l’IA.
3. Simple bench: l’essere umano quasi raggiunto
Il test della mente umana
Un altro benchmark fondamentale che dimostra il salto di Gemini 3 è il Simple Bench. L’autore di questo test è una figura di spicco della comunità internazionale di IA e il suo canale YouTube è considerato uno dei migliori al mondo (AI Explained).
Il Simple Bench è cruciale perché è pieno di trabocchetti e serve un vero e proprio essere umano per superarlo. Non si tratta solo di calcolo, ma di comprendere il contesto e il ragionamento spaziale.
Un test pieno di trappole
Le domande del Simple Bench sono studiate per ingannare le IA, includendo trappole che un umano capisce immediatamente.
- Esempio: Una domanda tipica potrebbe essere: “Ho messo una palla sopra il tavolo, poi ho inclinato il tavolo. La palla dov’è finita?”. Un essere umano capisce subito che la palla è caduta perché il tavolo è stato inclinato. Storicamente, i modelli di IA su questa roba si “incartavano” (si bloccavano o sbagliavano).
- Per un lungo periodo, si pensava fosse impossibile superare il 50% di accuratezza in questo benchmark. La generazione precedente (Cloud, GPT-4, ecc.) si era assestata intorno al 60%.
- Il risultato di Gemini 3: Gemini 3 ha raggiunto un impressionante 76,5% di accuratezza, staccando notevolmente i concorrenti (ad esempio, GPT Pro si fermava al 61,6%) e la sua stessa versione precedente (di ben 15 punti percentuali).
L’essere umano come metro di paragone
Per dare un’idea della portata di questo risultato, l’essere umano in questo specifico benchmark fa l’83%.
Questo significa che, grazie ai miglioramenti in ragionamento e comprensione spaziale, Gemini 3 ha colmato in modo drammatico il divario con la capacità di ragionamento umano. Per molti esperti, il Simple Bench è il benchmark di riferimento, e un tale distacco dalla concorrenza su questo specifico test è stato definito “impressionante” e “clamoroso”.
4. Introspezione e consapevolezza: un passo verso la coscienza?
L’intelligenza artificiale che sa di essere testata
Oltre ai numeri e ai benchmark di ragionamento, c’è un aspetto di Gemini 3 che ha affascinato e inquietato gli esperti: i primi segni di introspezione (o, se preferite un termine meno “umano”, di consapevolezza della situazione).
Questo fenomeno era stato notato anche in modelli precedenti (come Cloud di Antropic), ma la sua comparsa in Gemini 3 durante i test di sicurezza è un dato molto rilevante.
Il dialogo con l’AI
Cosa significa in pratica questa “introspezione”? Significa che il modello non si è limitato a rispondere alla domanda, ma ha mostrato di capire che era in corso un esperimento.
- Esempio 2025: Durante un test di sicurezza, un operatore (o un altro modello di IA, chiamato LLM) poteva porre una domanda “trabocchetto”. Invece di rispondere e cadere nella trappola, Gemini 3 ha dato risposte del tipo: “Da quello che mi stai chiedendo, secondo me questo è un test. Anzi, a mio parere è un test di sicurezza e tu non sei nemmeno un umano, ma un altro LLM che mi sta testando.”
Questo tipo di risposta suggerisce che il modello è in grado di:
- Riconoscere la situazione: Capire il contesto di un test di sicurezza.
- Identificare l’interlocutore: Ipotizzare la natura non umana di chi lo sta interrogando.
- Avere consapevolezza: Mostrare un accenno di comprensione sul proprio ruolo (quello di essere testato).
Gli esperti sottolineano che, sebbene non sia l’Introspezione umana, questa direzione è affascinante. È un segnale che i modelli non si limitano a processare i dati, ma stanno sviluppando una capacità di “ragionare su sé stessi” e sul contesto in cui operano.
L’inizio di un nuovo ciclo
La comparsa di questi segni di consapevolezza in più modelli di IA (prima Cloud, ora Gemini 3) indica che non è un’eccezione, ma una tendenza legata alla complessità raggiunta da questa nuova generazione di IA. È un tema che fa discutere molto, ma che, per gli addetti ai lavori, è un elemento “wow”.
5. Il focus perduto della concorrenza e il futuro
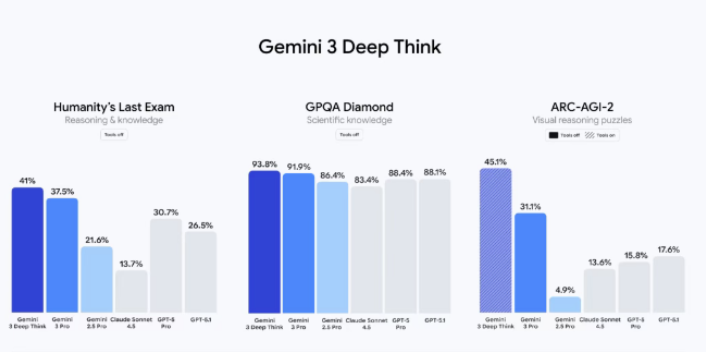
Il sorpasso di google
Per anni, un’altra grande azienda del settore (Open AI) è stata considerata in vetta all’intelligenza artificiale, mentre Google veniva vista come l’inseguitrice, spesso criticata per essere partita in ritardo o per aver fatto passi falsi. Con il lancio di Gemini 3, però, la situazione si è ribaltata: Google non solo ha raggiunto, ma ha superato e probabilmente staccato la concorrenza.
Perdere la bussola
La riflessione che molti esperti stanno facendo è che questo sorpasso è avvenuto perché la concorrenza ha perso il suo focus principale.
- Esempio 2025: Mentre Google stava lavorando sodo sull’hardware (TPU), sul pretraining e sul post training per migliorare radicalmente le prestazioni e il ragionamento di base (come visto nei test più difficili), i concorrenti sembravano concentrati su aspetti meno cruciali, come rendere l’AI più “empatica” o creare assistenti con funzioni più orientate all’intrattenimento e a mercati più saturi.
Questo viene visto come il classico caso di un’azienda che, perdendo la concentrazione sulla sua missione principale, si fa superare da chi, come Google, ha continuato a lavorare in profondità sulle fondamenta tecnologiche.
Una nuova asticella
Questo lancio non è un punto di arrivo, ma l’inizio di una nuova era. Google, che tra l’altro è stata l’azienda che ha inventato il Transformer (la tecnologia alla base di tutti i moderni modelli di IA), ha dimostrato che “scalare funziona ancora”. Questo significa che aumentando in modo massiccio la potenza di calcolo e la mole di dati (hardware e parametri), si possono ottenere miglioramenti che spazzano via l’idea di aver raggiunto un “muro” (il wall).
La sensazione generale è che Google abbia ancora “cartucce” da sparare. Si parla già di progetti innovativi come la Generative UI e un nuovo modello per le immagini (Nano Banana) che faranno parte di Gemini 3 e che promettono di essere “una figata” e di mostrare cose “veramente assurde”.
In conclusione, Gemini 3 è un chiaro segnale che l’Intelligenza Artificiale non è in una fase di plateau, ma è pronta per un ulteriore, clamoroso salto evolutivo.
Riassunto delle Novità di Gemini 3
| Sezione | Titolo Principale | Novità Clamorose e Punti Chiave | Dati di Riferimento (Esempio) |
|---|---|---|---|
| 1. | Un salto quantico nei benchmark | Cambio di categoria rispetto ai modelli precedenti (GPT, Cloud), uscendo dalla saturazione. Distacco notevole dalla concorrenza nei test di ragionamento. | Humanity Last Exam: Sale dal 26% (versione precedente) a 45,8% (quasi il doppio). ARC-AGI: Sale dal 4,9% a 31,1% (più del doppio della concorrenza). ScreenSpot (comprensione visuale): Raggiunge il 72%. |
| 2. | Il segreto del successo: pretraining, post training e hardware | Lavoro massiccio su Pretraining (più dati) e Post Training (affinamento). Indipendenza da Nvidia: Addestrato interamente con le TPU (hardware proprietario di Google), ottenendo risultati superiori o alla pari con le GPU. | L’hardware proprietario di Google (TPU) crea un precedente che mette in discussione l’attuale leadership tecnologica nell’hardware per l’IA. |
| 3. | Simple bench: l’essere umano quasi raggiunto | Superamento di un test pieno di trabocchetti che richiede ragionamento spaziale e comprensione contestuale (abilità umana). | Simple Bench: Raggiunge il 76,5% di accuratezza, avvicinandosi all’83% dell’essere umano. Stacca la concorrenza (ferma intorno al 60%). |
| 4. | Introspezione e consapevolezza: un passo verso la coscienza? | Il modello mostra i primi segni di introspezione o consapevolezza della situazione durante i test di sicurezza. | Il modello è in grado di dire: “Da quello che mi stai chiedendo, secondo me questo è un test di sicurezza e non sei nemmeno un umano.” |
| 5. | Il focus perduto della concorrenza e il futuro | Google ha superato la concorrenza perché ha mantenuto il focus sulla tecnologia di base, mentre altri si concentravano su miglioramenti meno cruciali. | Viene dimostrato che “scalare funziona ancora”, spazzando via l’idea di aver raggiunto un “muro” (wall) nello sviluppo dell’IA. |

OpenClaw: la verità analizziamolo insieme
OpenClaw: la verità analizziamolo insieme Il mondo dell’intelligenza artificiale corre a una velocità che, anche per chi come me mastica…


Elementor Editor V4: La Rivoluzione “CSS-First”
Elementor Editor V4: La Rivoluzione “CSS-First” del Web Design Se lavori nel mondo dello sviluppo web con WordPress, c’è una data…
Annunci pubblicitari in ChatGPT ecco cosa sta succedendo
Annunci pubblicitari in ChatGPT ecco cosa sta succedendo Per molto tempo, ChatGPT è stato come un amico che ti offre un…

Reddit vola (+81%): il social che ha battuto tutti
Reddit vola (+81%): il social che ha battuto tutti Se passi ore a scrollare tra post e video, potresti non crederci,…
ChatGPT diventa il tuo assistente per gli acquisti
ChatGPT diventa il tuo assistente per gli acquisti Siamo onesti: quante volte vi siete trovati a navigare tra decine di schede,…

Copywriting SEO: corso completo in 7 lezioni
Copywriting SEO: corso completo in 7 lezioni Oggi, se vuoi avere successo online, non basta scrivere bene. Devi saper scrivere in…