Scopri le novità del nuovo modello AI di OpenAI: GPT-4o

OpenAI ha recentemente lanciato il suo nuovo modello di intelligenza artificiale, GPT-4o, un’innovazione che promette di trasformare radicalmente il modo in cui interagiamo con i computer. Questo articolo esplorerà le nuove capacità di GPT-4o, le sue applicazioni pratiche e i miglioramenti rispetto ai modelli precedenti.
Una nuova era nell’interazione uomo-computer
Cos’è GPT-4o?
GPT-4o, dove “o” sta per “omni”, rappresenta un passo avanti significativo nella tecnologia AI. Questo modello è progettato per accettare input in qualsiasi combinazione di testo, audio, immagini e video, generando risposte che possono essere testi, audio o immagini. Questa capacità multimodale rende GPT-4o uno strumento incredibilmente versatile e potente.
Risposta in tempo reale
Una delle caratteristiche più sorprendenti di GPT-4o è la sua velocità di risposta. Il modello è in grado di rispondere a input audio in soli 232 millisecondi, con una media di 320 millisecondi, paragonabile ai tempi di risposta umani. Questo rende le conversazioni con l’AI molto più naturali e fluide rispetto ai modelli precedenti.
Un’unica rete neurale per tutte le modalità
A differenza dei modelli precedenti, che utilizzavano pipeline separate per trascrivere audio in testo, elaborare il testo e poi convertire il testo in audio, GPT-4o utilizza una singola rete neurale per gestire tutti questi compiti. Questo approccio integrato permette al modello di mantenere una comprensione più ricca del contesto, della tonalità e delle sfumature emotive, migliorando significativamente l’esperienza utente.
Esempi di applicazioni pratiche
Interazione tra due GPT-4o
GPT-4o può simulare interazioni complesse tra due entità AI, come conversazioni, giochi di società come “Carta, Forbici, Sasso” e persino armonizzare insieme in canzoni. Questo apre nuove possibilità per applicazioni creative e di intrattenimento.
Preparazione per interviste
GPT-4o è in grado di assistere nella preparazione di interviste, offrendo risposte simulate e feedback su possibili domande. Questa funzionalità è particolarmente utile per chi si prepara a colloqui di lavoro o interviste importanti.
Traduzione in tempo reale
Il modello è capace di tradurre discorsi in tempo reale, una funzione che può essere utilizzata in contesti internazionali per facilitare la comunicazione tra persone di diverse lingue.
Comprensione visiva e narrativa
GPT-4o eccelle anche nella comprensione delle immagini e nella narrazione visiva. Ad esempio, può descrivere dettagliatamente ciò che vede in una foto o un video, rendendo possibile nuove forme di assistenza visiva per non vedenti o ipovedenti.
Vedi alcuni video esempi direttamente dal canale YouTube di Open AI
Prestazioni e valutazioni
Benchmark tradizionali
In termini di valutazioni tradizionali, GPT-4o raggiunge livelli di prestazioni comparabili a GPT-4 Turbo per quanto riguarda il testo, il ragionamento e la codifica. Tuttavia, stabilisce nuovi standard per le capacità multilingue, audio e visive.
Riconoscimento vocale
GPT-4o migliora notevolmente le prestazioni di riconoscimento vocale rispetto a Whisper-v3, soprattutto per le lingue meno diffuse. Questo lo rende uno strumento più inclusivo e accessibile a una vasta gamma di utenti globali.
Traduzione audio
Il modello stabilisce un nuovo stato dell’arte nella traduzione del parlato, superando Whisper-v3 nei benchmark MLS. Questo miglioramento è cruciale per le applicazioni che richiedono traduzioni accurate e rapide.
Comprensione visiva
GPT-4o eccelle nella percezione visiva, ottenendo risultati di alto livello in benchmark come MMMU, MathVista e ChartQA. Questi risultati sono ottenuti con valutazioni zero-shot, dimostrando la capacità del modello di comprendere e analizzare immagini senza necessità di addestramento specifico su quei compiti.
Vediamo una galleria d’immagini sulle prestazione di GPT-4o riprese dal sito di OpenAI
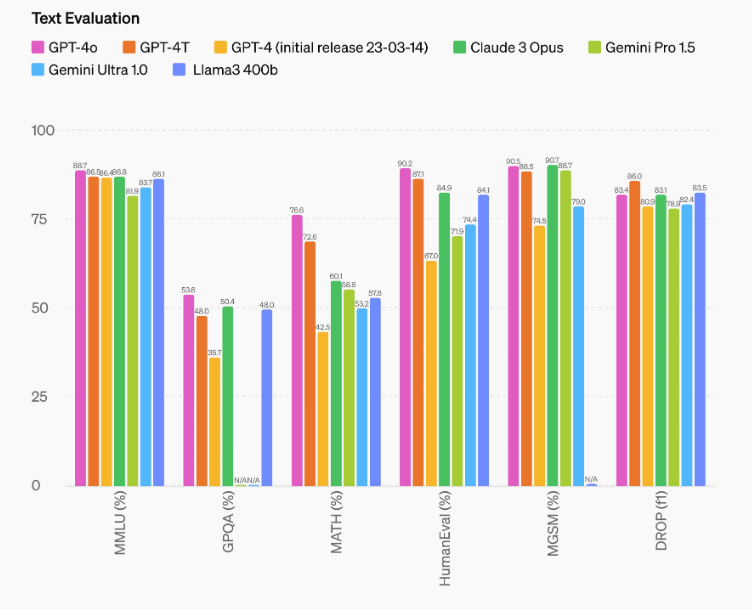

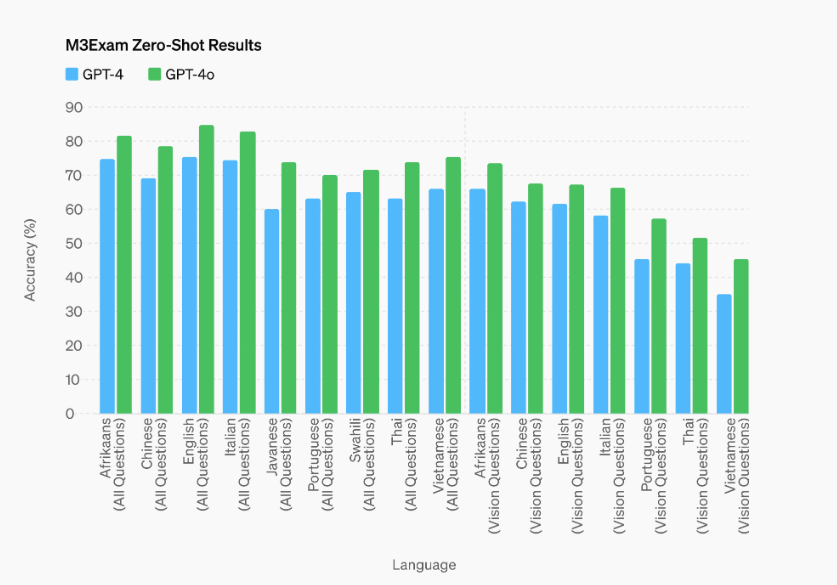
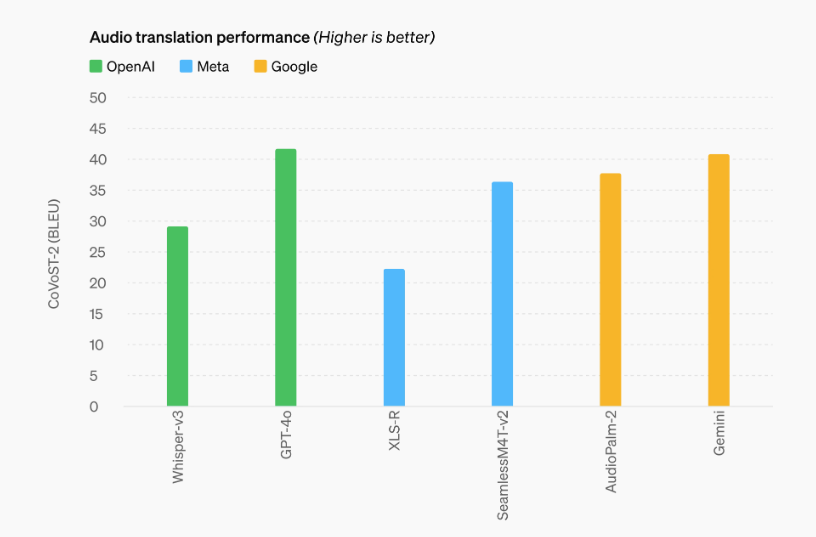

Compressione linguistica
Una delle innovazioni tecniche di GPT-4o è il nuovo tokenizzatore, che comprime in modo efficiente i dati linguistici, riducendo il numero di token necessari per rappresentare frasi in diverse lingue. Questo non solo migliora l’efficienza del modello, ma ne amplia anche l’accessibilità e l’efficacia in contesti multilingue.
Esempi di compressione dei token
- Gujarati: 4,4 volte meno token.
- Telugu: 3,5 volte meno token.
- Tamil: 3,3 volte meno token.
- Marathi: 2,9 volte meno token.
- Hindi: 2,9 volte meno token.
- Urdu: 2,5 volte meno token.
Questi miglioramenti rendono GPT-4o particolarmente potente per le lingue che tradizionalmente hanno una rappresentazione meno efficiente nei modelli di linguaggio.
Sicurezza e limitazioni
Sicurezza integrata
La sicurezza di GPT-4o è stata una priorità fin dalla progettazione. Il modello utilizza tecniche avanzate per filtrare i dati di addestramento e affinare il comportamento post-addestramento, assicurando che le interazioni siano sicure e appropriate.
Valutazioni esterne
Il modello è stato sottoposto a un’ampia valutazione da parte di esperti esterni in settori come la psicologia sociale, la parzialità e l’equità, e la disinformazione. Questi esperti hanno contribuito a identificare e mitigare i rischi potenziali introdotti dalle nuove modalità.
Limitazioni attuali
Nonostante i progressi, GPT-4o presenta ancora alcune limitazioni. Ad esempio, le modalità audio presentano rischi unici che necessitano di ulteriori perfezionamenti. Per il momento, le uscite audio saranno limitate a una selezione di voci preimpostate, rispettando le politiche di sicurezza esistenti.
Disponibilità del modello
Lancio e accesso
GPT-4o rappresenta un passo avanti significativo nell’usabilità pratica dell’intelligenza artificiale. A partire da oggi, le capacità di testo e immagine di GPT-4o sono disponibili su ChatGPT, con un accesso ampliato per gli utenti del livello gratuito e fino a 5 volte il limite di messaggi per gli utenti Plus.
Ecco un esempio di quando terminiamo i messaggi nella versione Gratuita di GPT-4o

Accesso API
Gli sviluppatori possono ora accedere a GPT-4o tramite l’API come modello di testo e visione. Questo modello è due volte più veloce, costa la metà e offre limiti di velocità cinque volte superiori rispetto a GPT-4 Turbo. Supporto per le nuove capacità audio e video di GPT-4o sarà presto disponibile per un gruppo selezionato di partner fidati.
Tabella di Resoconto
| Punto Importante | Dettagli |
|---|---|
| Nome del Modello | GPT-4o (Omni) |
| Tempo di Risposta Audio | Risposta in soli 232 ms, con una media di 320 ms, simile al tempo di risposta umano in una conversazione |
| Capacità Multimodali | Accetta input di testo, audio, immagini e video; genera output di testo, audio e immagini. Tutto elaborato dalla stessa rete neurale, consentendo una comprensione più ricca e risposte più naturali |
| Interazione e Musica | Può interagire con altri modelli GPT-4o, cantare e armonizzare, giocare a carta, forbice, sasso, e partecipare in situazioni umoristiche come raccontare barzellette o essere sarcastico |
| Narrazioni Visive | Capace di generare e manipolare immagini dettagliate, come mostrare un robot che scrive su una macchina da scrivere, e modificare scene in modo interattivo, come strappare un foglio di carta |
| Design dei Personaggi | Crea personaggi visivi dinamici e amichevoli, come Geary il robot, che può posare e svolgere attività come giocare a frisbee |
| Valutazione del Testo | Alto punteggio nelle valutazioni di ragionamento testuale: MMLU 0-shot CoT: 88,7%, MMLU 5-shot no-CoT: 87,2%. Utilizza la nuova libreria di valutazioni semplici di OpenAI |
| Riconoscimento Vocale | Miglioramento significativo nelle prestazioni di riconoscimento vocale rispetto a Whisper-v3, specialmente nelle lingue con meno risorse, fornendo trascrizioni più precise ed efficienti |
| Comprensione Multilingue | Supera GPT-4 nel benchmark M3Exam, che valuta la comprensione in più lingue e visioni complesse, mostrando risultati migliori in tutte le lingue testate |
| Sicurezza del Modello | Incorpora misure di sicurezza avanzate come il filtraggio dei dati e il raffinamento del comportamento mediante post-addestramento. Valutato da oltre 70 esperti esterni in psicologia sociale, equità e disinformazione. Implementa protezioni per gli output vocali |
| Disponibilità | Comincia a essere disponibile in ChatGPT per utenti gratuiti e Plus, con capacità estese nell’API per sviluppatori. Audio e video in fase alfa per partner selezionati. La nuova modalità vocale sarà presto lanciata per utenti ChatGPT Plus |
| Prestazioni Comparative | È 2 volte più veloce, metà del costo e consente 5 volte più limiti di velocità rispetto a GPT-4 Turbo, rendendo l’IA più accessibile ed efficiente per una vasta gamma di applicazioni |
Conclusione
GPT-4o di OpenAI rappresenta una rivoluzione nell’interazione uomo-computer, combinando capacità avanzate di testo, audio, immagini e video in un unico modello. Con risposte in tempo reale e una comprensione profonda dei contesti multimodali, GPT-4o promette di trasformare l’esperienza utente in numerosi campi. Restate sintonizzati per ulteriori aggiornamenti e applicazioni di questo straordinario modello di intelligenza artificiale.

Il browser diventa un agente: è iniziata la guerra dei
Nel 2026 il browser non serve più solo a navigare: sta diventando un agente AI capace di agire al posto…


ChatGPT 5.6 e ChatGPT Work: tutte le novità
ChatGPT 5.6 e ChatGPT Work: tutte le novità Di Daniele Forciniti ChatGPT 5.6 è la nuova generazione di modelli di intelligenza artificiale…

12 corsi gratuiti AI: i migliori sul web del 2026
12 corsi gratuiti AI: i migliori sul web del 2026 Di Daniele Forciniti Smettetela di improvvisare con l’IA: serve formazione concreta I corsi…

Corsi di Google con certificato: quali sono e come ottenerli
Corsi di Google con certificato: quali sono e come ottenerli Di Daniele Forciniti I corsi di Google con certificato sono percorsi formativi…

Claude Sonnet 5: tutte le novità del nuovo modello AI
Claude Sonnet 5: tutte le novità del nuovo modello AI di Anthropic Di Daniele Forciniti Claude Sonnet 5 è il nuovo modello…

Google AI mode sta cambiando Internet
Google AI mode sta cambiando Internet: ho analizzato cosa succede ai siti web e perché la SEO da sola non…

Aziende citate in ChatGPT: quante compaiono risposte AI
Aziende citate in ChatGPT: quante realtà italiane compaiono davvero nelle risposte dell’AI? Di Daniele Forciniti Se ti stai chiedendo quante aziende sono…

Google Discover 2026: cosa sta funzionando davvero
Google Discover 2026: cosa sta funzionando davvero Di Daniele Forciniti Google Discover 2026 oggi premia soprattutto contenuti originali, utili e coerenti con…